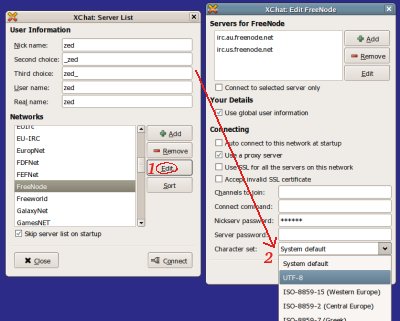
1) In the Server List GUI, you may select a different character-set to use for each IRC network. See the combo box "Character Set:" and make a selection. If the character-set you're after isn't listed, you may enter it manually. The conversions are performed by ICONV, which knows hundreds of different character-sets. On a UNIX system you can type iconv --list in a terminal for a complete list.
2) Change your system's character-set (this method is only for Unix, not Windows). Consult your distribution's docs on how to do this. You can do it temporarily from a shell:
$ export CHARSET=ISO-8859-15 $ xchat &
XChat will now use ISO-8859-15 for IRC traffic (if all Networks are set to "System Default", like in the picture above).
XChat 2.6.8 and above gives you a new character set choice: IRC (Latin-1/UTF-8 hybrid) You can choose this in the Network List's EDIT window, or by typing /charset IRC. Below is a description of how it works. Sending text: ~~~~~~~~~~~~~ If your text contains only characters that fit inside the CP1252 code page (aka Windows Latin-1), the entire line will be sent that way. mIRC users should see it correctly. XChat users who are using UTF-8 will also see it correctly, because it will fail UTF-8 validation and will be assumed to be CP1252, even by older XChat versions. If the text doesn't fit inside the CP1252 code page, (for eaxmple if you type Eastern European characters, or Russian) it will be sent as UTF-8. Only UTF-8 capable clients will be able to see these characters correctly, they include: 1. XChat 2.6.8+ set to "IRC". OR 2. Older XChat set to "UTF-8", but not Latin-1/ISO-8859-1(5)/CP1252. OR 3. Newer mIRC set to "UTF-8". OR 4. Any UTF-8 enabled client. Receiving text: ~~~~~~~~~~~~~~~ If incoming text is valid UTF-8, it will be interpreted as such. If it fails validation, a CP1252 -> UTF-8 conversion is performed. This allows you to see non-ASCII from mIRC users (non-UTF-8) and other users sending you UTF-8.